Basics
Cluster description
The computing cluster is made up of 3 compute nodes designated p1-p3. They use a shared storeage for the /home directory so the same data is available from each individual node. The IP addresses for the nodes are the following:
p1 - 10.18.0.11
p2 - 10.18.0.12
p3 - 10.18.0.13
Each node has 24 cores. This means you can run 24 processes at the same time. Additional p1-3 contain 64Gb RAM. If you are running a programs using many cores or a log of memmory please check if anyone else is using some resource bedore running a job. Double check if there are enough computing reseources available before running your job (see below). If too much resource is used the node can freeze up and must be restarted - resulting in data loss.
Logging in and transferring data
You will be given a a login profile to one of the nodes with a username and a password. Log in to the cluster using the following command:
ssh -X username@ip-address
The -X allows for X-forwarding and the loading of GUI from the cluster on your screen
You can transfer data over from the cluster onto your own computer using Filezilla or scp
Filezilla
Filezilla is a software you can download and is a bit more user friendly. Use the following credentials:
- Host - ip address (e.g. 10.18.0.11)
- Username - your user name (probably your first name)
- Password - your assigned password
- Port - 22
You can then visually navigate through the directory structure of both your local computer (left panel) and the remote server (right panel).
SCP
SCP can be used to transfer data through ssh. The command should be used as following:
scp username@ip-address:/path/to/file .
This will transfer a file at /path/to/file into your current working directory on your local machine. Wildcards (* and ?) can be used to create multiple selections, as can numerical ranges (e.g. {01..22} will iterate through values 01, 02, 03, etc. until 22).
Basic commands
Here is a list of usefull commands where input parameters (often files or folders) are designated using "<parameter>":
| Command | Description |
|---|---|
| ls | See all files and folders in your current directory |
| cd <directory> | Change directory to <directory> |
| top | See a list of all current running processes (use "q" to quit) |
| gunzip <file.gz> | Unzip a gzipped file |
| gzip <file> | Compress (with gzip) a file to save disk space |
| cp <file1> <file2> | Copy from <file1> to <file2> |
| tar -zxvf <tarball.tar.gz> | Extract a tarball into a directory |
| tar -zcvf <name>.tar.gz <directory> | Compress a directory into a tarball |
| less | Interactively open a file for viewing |
| cat <file1> | Print file to standard output (terminal) |
| cat <file1> <file2> | Concatenate two files and return to output |
| <command> > <file> | Write a commands output to a file |
| <command> >> <file> | Append a commands output to a file |
| nano <file> | Open a file in the command line editor (better than vim or emacs, only nerds use those) |
| passwd | Allows you to change your password |
Navigation Tips
Here is a list of useful shortcuts for navigating within the unix file system.
| Command | Description |
|---|---|
| . | Current directory |
| .. | Parent directory |
| / | Root directory |
| ~ | Home directory |
Checking resource usage
When logged into one of the nodes you can use the top command to check resrouce useage. Press q to exit top. You will see a window similar to the one below:
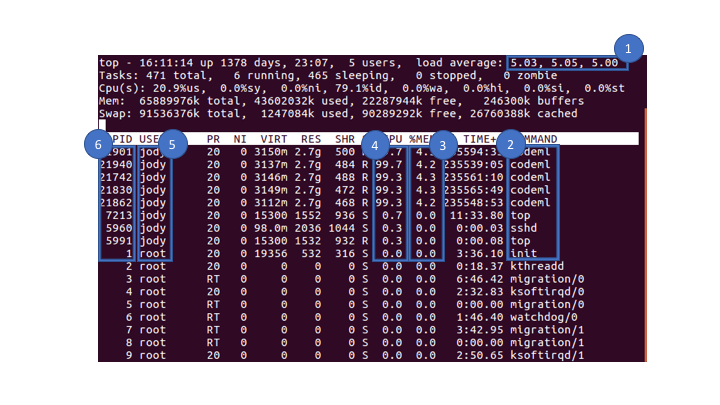
The things to look at are:
- Total load - The three numbers represent the load on the server over 1, 5 and 5 minutes.
- Program names - The names of the programs currently running. Type
cto get the whole command - Memory usage - The memory usage of the program
- CPU usage - The thread usage of each program
- User name - The user who is running the program
- PID - The process ID (useful if you need to kill a job).
Estimating CPU usage
If one program is running using 1 thread it will add a load of 1. Similarly if you are running 5 programs with each using 1 thread the load will be 5. If you are using a multithread program then it will use multiple CPUs. The load is proportional to the number of CPUs it uses. For example if you are running one program which is using 5 threads then the load will be 5. The load should never exceed the number of cpus in the system.
The CPU usage for a single job can be found by looking at the CPU usage column of top. You will see that some jobs use a log of CPU (close to %100 or more if multithreaded). A program using one thread will use %100, this number will scale to the number of threads used. Some programs will use very little (almost 0%) and not actively running.
For example the nodes each have 24 CPUs and so the total load should ideally be less than 24. When it exceeds this limit the programs might crash or run slowly. In the example above a jobs should not be run which uses than 19 threads.
Estimating memory usage
Programs can also fail or run slowly if there is not enough memory. The proportion of memory can be estimated by finding the active jobs (i.e. those that use 100% or more CPU) and sum up the %CPU usage column for these programs. In the example above there are 5 active programs which use ~4.2% of the total memory each. This equates to ~21% of the memory in use. This particular node is p3 which has 64GB of RAM. This means that there is 64*0.79 ~= 50.5 GB of RAM free. If your program might use more than that, it would be worthwhile to swtich to another node.
Killing Jobs
Jobs can be stopped using the kill command. First you should find the PID of the job you want to stop. Then you can simple type: kill <pid>